
This is part 4 and the final part of the series on how to speed up an interpreter written with PyPy by adding JIT hints to the interpreter. Part 1 described how to control the extent of tracing. Part 2 described how to influence the optimizer with promotion and pure functions. Part 3 described a simple object model and how it can be optimized by doing small rewrites. In this (short) post I present some benchmarks.
Benchmarks
For the benchmarks I ran a subset of the benchmarks on http://speed.pypy.org with CPython and four different executables of PyPy's Python interpreter (all with a JIT). The executables contain all combinations of enabling maps (which make instance attributes fast) and type versions (which makes method lookup fast).
- pypy-slow: contains neither maps nor type versions.
- pypy-map: contains maps but not type versions.
- pypy-version: contains type versions but not maps.
- pypy-full: contains both maps and type versions
The results are as follows:
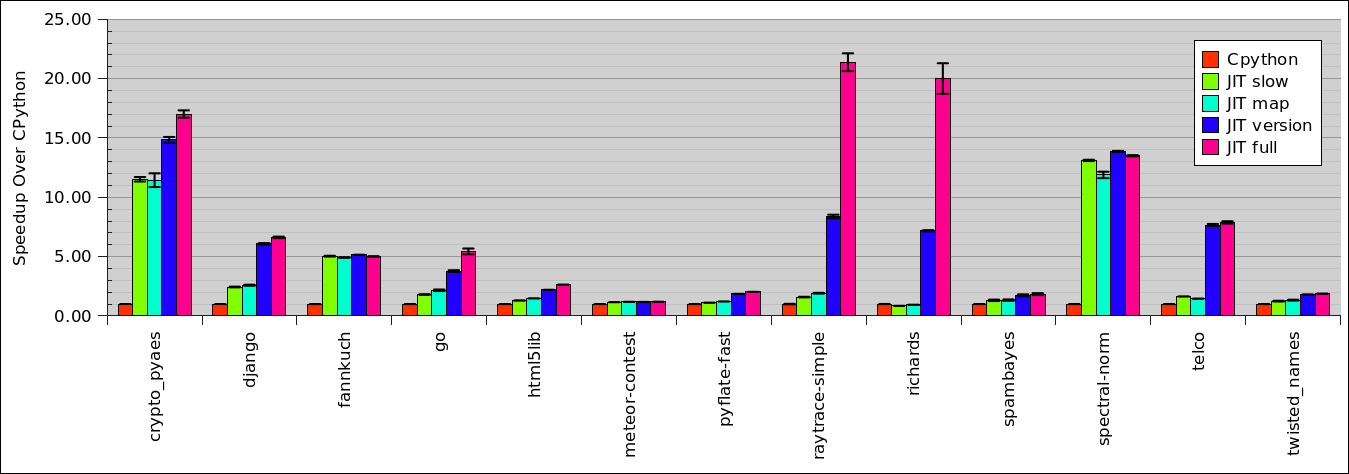
The graph shows the speedup over CPython's numbers. The results are quite interesting. Maps by themselves do not speed up much over the bare JIT, whereas typed versions alone improve on the JIT baseline in many cases. However, maps are not useless. In combination with type versions they add a nice improvement over just type versions in a number of benchmarks (most notably raytrace-simple and richards but also in crypto-pyaes, django and go).
It's clear that type versions can be arbitrarily effective. A method lookup on a class can be arbitrarily slow, if the inheritance hierarchy becomes deeper and deeper. The full lookup is replaced by one promotion if type versions are enabled.
Maps on the other hand always replace one dict lookup with one promotion. Since dict lookups are already very fast, this by itself does not lead to a gigantic improvement. Only in combination with type versions do they show their full potential.
9 comments:
It's not clear to me why version + maps combine so well. Maps should effectively eliminate lookups on the instance dict and versions eliminate lookups on the class dict. Both versions would seem to eliminate different classes of lookups, so I'm not seeing why we have dramatic improvement when using them together.
I'm not an expert at CPU architecture, but ISTM eliminating both can eliminate a large number of memory reads which would help with pipelining and other very low level optimizations.
@Winston: I actually have no clue :-). The numbers are hard to deny though. I plan to stare at the traces a bit next week, can comment here if I find something interesting.
@Winston: ok, I probably found out. Your reasoning is too simple because usually you do several lookups on the same object in a row. Every lookup looks first in the class, then in the instance. So it looks a bit like this:
lookup name1 in obj.__class__
lookup name1 in obj.__dict__
lookup name2 in obj.__class__
lookup name2 in obj.__dict__
lookup name2 in obj.__class__
lookup name2 in obj.__dict__
when using maps, every lookup in the dict is simply reading the map, promoting it and then a read. after the promotion of the map, the instance's layout is fully known. however, if type versions are disabled, the lookups in the class are complex operations that are opaque to the JIT. Therefore the JIT assumes they can change the layout and thus the map of the object.
If you also enable type versions, then the class lookups are understandable to the JIT. therefore the JIT can see that the class lookup didn't change the layout of the class. This means that after the first instance lookup, the following instance lookups cost nothing at all.
I think an important improvement brought about by maps is the memory footprint reduction.
It won't matter all the time, but it makes all classes as space-efficient as if they used __slots__, all automagically, which is no small thing.
For programs that handle lots of small objects, this can really make a difference, in memory consumption and speed (less memory to shuffle around will invariably be faster)
Perhaps the benchmark suite doesn't have enough of those cases.
@cfbolz I think one reason why maps+version tags are fast is because we lack jit.unroll_safe on several lookup functions when version tags are disabled. Marking them as unrollable would speed things up.
The reasoning behind this is that old style classes which have maps, but no version tags are much faster than new style classes with version tags disabled.
Thanks for taking the time to answer my query.
The use of class versions eliminates the opaque function being called because the JIT knows the return will be constant. This allows optimizations to work correctly. But this makes me wonder how much of the improvement is due to class versions and how much is due to lack of opaqueness.
At any rate, I always find the posts on this blog very interesting. It definitely some neat stuff you are doing here.
@fijal I thought old-style classes had celldicts? That's yet another thing, but your point is still correct.
I'd love to see a blog post about conventions to favor or avoid while writing python code to best take advantage of these excellent features. For example, your previous post implied something like this would be faster than changing the class directly:
class Counter(object):
....def __init__(self):
........self.count = 0
....def increment(self):
........self.count += 1
class Many(object):
....counter = Counter()
....def __init__(self):
........self.counter.increment()
Granted, it would be preferable, from a coding standpoint, to just use a simple class attribute, but the adaptations that would likely work best for the pypy JIT seem like far smaller divergences from the 'ideal' python than many other lengths people go to when coding for speed, particularly compared to something like cython.
Post a Comment