
Wednesday, November 28, 2007
PyPy Google Tech Talk
The Google Tech Talk that Samuele, Armin, Jacob and Laura gave during the US trip is now on YouTube: http://www.youtube.com/watch?v=GnPmErtqPXk
Sunday, November 25, 2007
Sprint Pictures
The obligatory sprint picture post...
 Alexander Schremmer, Armin Rigo, Maciek Fijalkowski, Antonio Cuni
Alexander Schremmer, Armin Rigo, Maciek Fijalkowski, Antonio Cuni
 Anders Chrigström, Samuele Pedroni, Laura Creighton, Jacob Hallén, Carl Friedrich Bolz, Richard Emslie, Maciek Fijalkowski, Armin Rigo
Anders Chrigström, Samuele Pedroni, Laura Creighton, Jacob Hallén, Carl Friedrich Bolz, Richard Emslie, Maciek Fijalkowski, Armin Rigo
 Holger Krekel
Holger Krekel
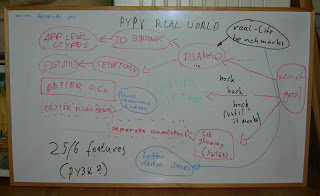 Whiteboard with "real world goals" dependencies.
Whiteboard with "real world goals" dependencies.
 Alexander Schremmer, Armin Rigo, Maciek Fijalkowski, Antonio Cuni
Alexander Schremmer, Armin Rigo, Maciek Fijalkowski, Antonio Cuni
 Anders Chrigström, Samuele Pedroni, Laura Creighton, Jacob Hallén, Carl Friedrich Bolz, Richard Emslie, Maciek Fijalkowski, Armin Rigo
Anders Chrigström, Samuele Pedroni, Laura Creighton, Jacob Hallén, Carl Friedrich Bolz, Richard Emslie, Maciek Fijalkowski, Armin Rigo
 Holger Krekel
Holger Krekel
 Whiteboard with "real world goals" dependencies.
Whiteboard with "real world goals" dependencies.
Sprint Discussions: Wrapping External Libraries
A more technical discussion during the sprint was about the next steps for the external module problem (minutes). One of PyPy's biggest problems in becoming more generally useful are C extension modules, which can't work with PyPy's Python interpreter. We already reimplemented many of the more commonly used extension modules in CPython's standard library in Python or RPython. However, there are more missing and there is no way to implement all the extension modules that other people have written.
 Whiteboard after the discussion.
Whiteboard after the discussion.
Therefore we need a different approach to this problem. Extension modules are commonly written for two different reasons, one being speed, the other being wrapping non-Python libraries. At the moment we want mostly to approach a solution for the latter problem, because we hope that the JIT will eventually make it possible to not have to write extension modules for speed reasons any more.
There are two rough ideas to approach this problem in the near future (there are other, more long-term ideas that I am not describing now): One of them is to add the ctypes module to PyPy's Python interpreter, which would mean re-implementing it since the existing implementation is written in C.
The other way would be to work on the existing way to get extensions in that PyPy provides, which are "mixed modules". Mixed modules are written in a combination of RPython and normal Python code. To then wrap C libraries you would use rffi, which is the foreign function interface of RPython.
 The discussion round: Maciek Fijalkowski, Armin Rigo, Richard Emslie, Alexander Schremmer.
The discussion round: Maciek Fijalkowski, Armin Rigo, Richard Emslie, Alexander Schremmer.
In the meeting it was decided to first go for a ctypes replacement. The replacement would be written in pure Python, we already have a very thin wrapper around libffi which the new ctypes implementation would use. The goal to reach would be to get the pygame implementation in ctypes to run on PyPy.
To make ctypes more useful in general to write this kind of wrappers, we will probably extract some code that we have already written for PyPy's own usage: it gives a way to write "imprecise" declarations ("a structure with at least fields called x and y which are of some kind of integer type") and turn them into exact ctypes declarations, internally using the C compiler to inspect the platform headers.
After this is done we should approach separate compilation so that developing modules in RPython has a quicker turnaround time. This is somewhat involved to implement for technical reasons. There are ideas how to implement it quickly to make it usable for prototyping, but it's still a lot of work.
Sprint Discussions: Releases, Testing
During the sprint we had various discussions about technical issues as well as planning discussions about how we want to go about things. One of them was about the stability of PyPy, how to ensure stability, how to handle releases and approaches to being more "usable". I will describe this discussion in this post (there are also minutes of the meeting).
 The Meetings whiteboard
The Meetings whiteboard
 The Meetings whiteboard
The Meetings whiteboard
First we discussed the current situation in terms of testing. PyPy has been extremely testing-oriented from the start, it is being developed almost exclusively in test-driven-development style. To deal with the large number of tests we already have some infrastructure in place:
- we run all of PyPy's tests nightly on a Linux machine
- we translate a PyPy Python interpreter every night and use that to run the CPython compliance tests against it, also on a Linux machine
- we translate several Python interpreters every night and run benchmarks against them on a PowerPC running Mac OS X
As you can see, we are lacking in the Windows testing area, which is an even worse problem because none of the currently active developers has Windows as his primary OS. We should improve this by finding a Windows machine where the tests are run nightly and where we can log in to try bug-fixes quickly. The latter bit is important, we had a nightly windows test run before (thanks to Scott Dial) but it didn't help, because even if you tried to fix a bug you would have to wait until the next night to see whether it worked.
Another very serious problem is that of aggregation: we have these various test runs that all have a web interface to check for errors but there is no easy way to find out which tests failed. You have to go to each page and even some sub-pages to see what needs fixing, which is a tedious process. The idea for solving this is aggregate all the available information into some sort of testing-entry-point page that gives a quick overview of the regressions that happened during the night. It's not clear whether we can achieve that with existing tools (buildbots or whatever), but we will investigate that.
Releases
The discussion about releases was more on a fundamental and less on a concrete level (especially when it comes to time-frames). We discussed what it means to make a release, because obviously it is more than just taking an SVN revision and putting a tarball of it onto the webpage. During the EU period we were required to make several releases, but those were not really meant to be more than technology previews for the brave adventurers to try. In the future we have the goal to release things that are more stable and hopefully more practically useful. The plan is to use medium-sized Python applications that have a chance to run on top of PyPy because they don't use too many extension modules (web apps being likely candidates) and that have good unit-tests themselves. The first step would be to find some applications that fit this description, fix the bugs that prevents PyPy from running them and from then on run them nightly on one of the testing machines to check for regressions. This would allow us to be more confident when stating that "PyPy works".
Another thing to keep in mind for releases is the special features that our Python interpreter provides (e.g. the thunk and the taint object space, our stackless features, transparent proxies, sandboxing, special object implementations). Those features are neither tested by the CPython tests nor by any existing applications. Therefore we cannot really be confident that these features work and don't have too many bugs (in fact, the first time somebody really use the become feature of the thunk space in earnest he found a serious bug that is not fixed so far). To get around this problem, we plan to write small-to-medium sized example applications for each of these features (for stackless we can maybe use one of the existing stackless examples). This will hopefully find bugs and will also make it possible to evaluate whether the features make sense from a language design point of view.
A minor thing to make releases easier is to be able to not only have the tests be run once a night but also be able to trigger them manually on the release branch before doing the release.
Since we decided that the releases we make should be stable and usable, we also discussed how we would go about making new "cool things" like features, experiments etc. better known. The consensus was that this blog is probably the best forum for doing this. In addition we discussed having a stabler snapshot of the trunk made to ensure that people wanting to play around with these features don't accidentally get a broken version.
Helping Out
Right now we are still in cleanup mode (the cleanup sprint is nearly done, but we haven't finished all the cleanups yet), so we won't be able to start on the above things right now. However, they will have a strong focus soon. So if you are interested in trying out to run programs on top of PyPy or writing new ones that use the new features you are most welcome to do so and we will try to fix the bugs or help you doing it (of course some tolerance against frustration is needed when you do that, because the bugs that turn up tend to be obscure). We have not been perfect at this in the past, but this will have to change.
Thursday, November 22, 2007
Ropes branch merged
This afternoon we merged the ropes branch that I have been working on on the side for a while (also to cut down the number of currently active branches a bit, since we are doing major cleanups right now). It contained a new (optional) implementation of the unicode type using the rope data structure. Ropes essentially use concatenation trees to represent strings. The leaves of the trees contain either byte arrays or arrays of unicode characters.
 Of course the fact that ropes are used is mostly completely transparent to the user (as usual in the pypy world :) ). Normal and unicode strings are implemented with them, but just from the behavior of these types the user has a hard time noticing. Of course there are significant changes in performance (in both directions).
Using ropes to implement strings has some interesting effects. The most obvious one is that string concatenation, slicing and repetition is really fast (I suspect that it is amortized O(1), but haven't proved it). This is probably not helping most existing Python programs because people tend to code in such a way that these operations are not done too often. However, with ropes it is possible to do something like this:
Of course the fact that ropes are used is mostly completely transparent to the user (as usual in the pypy world :) ). Normal and unicode strings are implemented with them, but just from the behavior of these types the user has a hard time noticing. Of course there are significant changes in performance (in both directions).
Using ropes to implement strings has some interesting effects. The most obvious one is that string concatenation, slicing and repetition is really fast (I suspect that it is amortized O(1), but haven't proved it). This is probably not helping most existing Python programs because people tend to code in such a way that these operations are not done too often. However, with ropes it is possible to do something like this:
 Of course the fact that ropes are used is mostly completely transparent to the user (as usual in the pypy world :) ). Normal and unicode strings are implemented with them, but just from the behavior of these types the user has a hard time noticing. Of course there are significant changes in performance (in both directions).
Using ropes to implement strings has some interesting effects. The most obvious one is that string concatenation, slicing and repetition is really fast (I suspect that it is amortized O(1), but haven't proved it). This is probably not helping most existing Python programs because people tend to code in such a way that these operations are not done too often. However, with ropes it is possible to do something like this:
Of course the fact that ropes are used is mostly completely transparent to the user (as usual in the pypy world :) ). Normal and unicode strings are implemented with them, but just from the behavior of these types the user has a hard time noticing. Of course there are significant changes in performance (in both directions).
Using ropes to implement strings has some interesting effects. The most obvious one is that string concatenation, slicing and repetition is really fast (I suspect that it is amortized O(1), but haven't proved it). This is probably not helping most existing Python programs because people tend to code in such a way that these operations are not done too often. However, with ropes it is possible to do something like this:
Python 2.4.1 (pypy 1.0.0 build 48942) on linux2 Type "help", "copyright", "credits" or "license" for more information. >>>> import sys >>>> a = "a" * sys.maxint >>>> hash(a) -768146060So somebody who is targeting a Python implementation that has ropes could write his code in such a way that this is taken into account. Another interesting feature is that ropes try to share as much data as possible with each other, so if you create a large slice of a large string, the slice is not going to take much additional memory. One of the most interesting use-cases of ropes are together with unicode. The leaf nodes of a rope unicode string can be either a byte array or an array of unicode characters. This means that a unicode string that uses only characters that are latin-1 or ascii will use one byte of memory per character. If a unicode string contains mostly only unicode characters that are latin-1 and a few that are not, it will still use 1 byte for most of the latin-1 characters. This property also allows really fast encoding and decoding of unicode strings as long as they don't contain non-latin-1 characters (only with certain encodings of course):
>>>> s = "a" * sys.maxint
>>>> u = s.decode("ascii")
>>>> u = s.decode("latin-1")
>>>> u = s.decode("utf-8")
Again, encoding and decoding strings that contain a few non-latin-1 characters is again efficient:
>>>> u = "a" * 100000000 + u"\uffff"
>>>> s = u.encode("utf-8")
>>>> len(s)
100000003
I am not completely certain how useful this behaviour is for real-life applications, but it's kind of cool :-). It saves memory for european languages that contain few non-ascii characters.
Of course there is at least one down-side to all of this, which is that string indexing is not O(1) any longer, because we have to walk down the tree to find the correct leaf where the character is actually in. I have not measured much, but I expect it to be quite fast in practice, because the trees are never deeper than 32 nodes.
Monday, November 19, 2007
PyPy cleanup sprint startup
The following week we will have a sprint in Gothenburg to clean up the PyPy codebase and make it ready for future developments. So far, only a few people are here, the others will arrive this afternoon.
 The Älvsborgsbron in Gothenburg from the ferry I took to get there.
The Älvsborgsbron in Gothenburg from the ferry I took to get there.
 The Älvsborgsbron in Gothenburg from the ferry I took to get there.
The Älvsborgsbron in Gothenburg from the ferry I took to get there.
Friday, November 9, 2007
Unicode support in RPython
In the recent days we (Carl Friedrich, Anto and me) implemented native unicode support for RPython. This means that now you can write u'xxxx' directly in your RPython program, as well as unicode(some_string_variable) and most of the unicode methods should work as well. The things that don't work, are operations that require the unicode database (such as .upper() and friends) and encodings (unicode(x, encoding) for example). Right now our python interpreter does not use this at all, but that's the next step.
Cheers,
fijal
Cheers,
fijal
Wednesday, November 7, 2007
The PyPy Road Show (1): New York and IBM
We're slowly getting adjusted to the jet-lag (except maybe Samuele). Time to blog...
The past two days at IBM, in New York, have been quite interesting. The place is a research center. Feels University-like, but meetings rooms have no windows and climatization fixed on "polar" settings. The building is of course heated at this time of the year, and then the meeting rooms are climatized... I guess that just doesn't make sense to me.
We gave a 1h30 talk to a general audience first. Then we had a compact schedule of meetings with various people or groups of people. In the early preparations for this trip we planned to stay only one day, but Martin Hirzel, our host, found too many people that wanted to talk with us :-)
I think that both us and most of the people we talked with got interesting things out of the meetings. On our side, let me point a few highlights.
We asked two people that worked on the GCs for the Jikes RVM if reusing them for RPython programs would make sense. They didn't scream "you're mad!", so I guess the answer is yes. Apparently, it has been done before, too. I'm still not sure I got this right, but it seems that Microsoft paid someone money to integrate them with Rotor... Then the real-time garbage-collection guys explained to us the things that we need to take care about when writing a VM: real-time GC needs not only write barriers and read barriers, but pointer-equality-comparison barriers... They have bad memories of trying to add a posteriori this kind of barrier into existing VMs, so it took us a bit of explaining to make them realize that adding new kinds of barriers is mostly trivial for us (I'm still not 100% sure they got it... bad memories can stick hard).
Then we had discussions with JIT people. Mostly, this allowed us to confirm that Samuele has already got a good idea about what Java JITs like Hotspot can do, and in which kind of situation they work well. As expected, the most difficult bit for a PyPy-like JIT that would run on top of a JVM would be the promotion. We discussed approaches like first generating fall-back cases that include some instrumentation logic, and regenerating code with a few promoted values after some time if it seems like it will be a gain. Replacing a method with a new version is difficult to do in a way that is portable across Java VMs. There are still possible workarounds, but it also means that if we really want to explore this seriously, we should consider experimenting with specifics VMs - e.g. the Jikes RVM gives (or could be adapted to give) hooks to replace methods with new versions of them, which is something that the JVM's own JIT internally does all the time.
We showed the taint object space and the sandboxed PyPy to several groups of security people. I won't say much about it here, beyond the fact that they were generally interested by the fact that the corresponding code is very short and easy to play with. They are doing a lot on security in Java and... PHP, for web sites. Someone could write a PHP interpreter (!) in PyPy to get the same kind of results. But as Laura and Samuele put it, there are things in life you do for fun, and things you do for money :-)
We're in Vancouver today and tomorrow. More about this later...
Armin Rigo
The PyPy Road Show
Armin Rigo, Samuele Pedroni, Laura Creighton and Jacob Hallén are on a two-week-trip through the USA and Canada, to present PyPy to various companies and institutions. The next few blog entries will cover our experiences and adventures.
Here is a glimpse of our schedule (all November 2007):
- 4th: Chigaco
- 5th-6th: New York
- 7th-8th: Vancouver
- 9th-18th: San Francisco and the Bay Area
Subscribe to:
Posts (Atom)