
We have released PyPy2.7 v5.6 [0], about two months after PyPy2.7 v5.4. This new PyPy2.7 release includes the upstream stdlib version 2.7.12.
We continue to make incremental improvements to our C-API compatibility layer (cpyext). We pass all but 12 of the over-6000 tests in the upstream NumPy test suite, and have begun examining what it would take to support Pandas and PyQt.
Work proceeds at a good pace on the PyPy3.5 version due to a grant from the Mozilla Foundation, and some of those changes have been backported to PyPy2.7 where relevant.
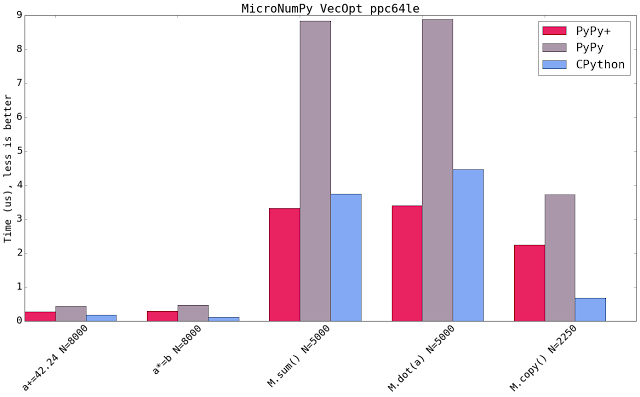
The PowerPC and s390x backend have been enhanced with the capability to use SIMD instructions for micronumpy loops.
We changed
timeit to now report average +/- standard deviation, which is better than the misleading minimum value reported in CPython.We now support building PyPy with OpenSSL 1.1 in our built-in _ssl module, as well as maintaining support for previous versions.
CFFI has been updated to 1.9, improving an already great package for interfacing with C.
As always, this release fixed many issues and bugs raised by the growing community of PyPy users. We strongly recommend updating. You can download the PyPy2.7 v5.6 release here:
Downstream packagers have been hard at work. The Debian package is already available, and the portable PyPy versions are also ready, for those who wish to run PyPy on other Linux distributions like RHEL/Centos 5.
We would like to thank our donors for the continued support of the PyPy project.
We would also like to thank our contributors and encourage new people to join the project. PyPy has many layers and we need help with all of them: PyPy and RPython documentation improvements, tweaking popular modules to run on pypy, or general help with making RPython’s JIT even better.
What is PyPy?
PyPy is a very compliant Python interpreter, almost a drop-in replacement for CPython 2.7. It’s fast (PyPy and CPython 2.7.x performance comparison) due to its integrated tracing JIT compiler.We also welcome developers of other dynamic languages to see what RPython can do for them.
This release supports:
- x86 machines on most common operating systems (Linux 32/64 bits, Mac OS X 64 bits, Windows 32 bits, OpenBSD, FreeBSD)
- newer ARM hardware (ARMv6 or ARMv7, with VFPv3) running Linux,
- big- and little-endian variants of PPC64 running Linux,
- s390x running Linux
What else is new?
(since the release of PyPy 5.4 in August, 2016)
There are many incremental improvements to RPython and PyPy, the complete listing is here.
Cheers, The PyPy team
[0] We skipped 5.5 since we share a code base with PyPy3, and PyPy3.3-v.5.5-alpha was released last month


{kind=link}