This afternoon we merged the
ropes branch that I have been working on on the side for a while (also to cut down the number of currently active branches a bit, since we are doing major cleanups right now). It contained a new (
optional) implementation of the unicode type using the
rope data structure. Ropes essentially use concatenation trees to represent strings. The leaves of the trees contain either byte arrays or arrays of unicode characters.
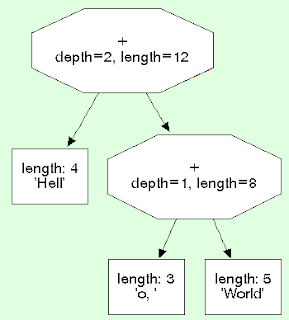
Of course the fact that ropes are used is mostly completely transparent to the user (as usual in the pypy world :) ). Normal and unicode strings are implemented with them, but just from the behavior of these types the user has a hard time noticing. Of course there are significant changes in performance (in both directions).
Using ropes to implement strings has some interesting effects. The most obvious one is that string concatenation, slicing and repetition is really fast (I suspect that it is amortized O(1), but haven't proved it). This is probably not helping most existing Python programs because people tend to code in such a way that these operations are not done too often. However, with ropes it is possible to do something like this:
Python 2.4.1 (pypy 1.0.0 build 48942) on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>>> import sys
>>>> a = "a" * sys.maxint
>>>> hash(a)
-768146060
So somebody who is targeting a Python implementation that has ropes could write his code in such a way that this is taken into account. Another interesting feature is that ropes try to share as much data as possible with each other, so if you create a large slice of a large string, the slice is not going to take much additional memory.
One of the most interesting use-cases of ropes are together with unicode. The leaf nodes of a rope unicode string can be either a byte array
or an array of unicode characters. This means that a unicode string that uses only characters that are latin-1 or ascii will use one byte of memory per character. If a unicode string contains mostly only unicode characters that are latin-1 and a few that are not, it will still use 1 byte for most of the latin-1 characters. This property also allows really fast encoding and decoding of unicode strings as long as they don't contain non-latin-1 characters (only with certain encodings of course):
>>>> s = "a" * sys.maxint
>>>> u = s.decode("ascii")
>>>> u = s.decode("latin-1")
>>>> u = s.decode("utf-8")
Again, encoding and decoding strings that contain a few non-latin-1 characters is again efficient:
>>>> u = "a" * 100000000 + u"\uffff"
>>>> s = u.encode("utf-8")
>>>> len(s)
100000003
I am not completely certain how useful this behaviour is for real-life applications, but it's kind of cool :-). It saves memory for european languages that contain few non-ascii characters.
Of course there is at least one down-side to all of this, which is that string indexing is not O(1) any longer, because we have to walk down the tree to find the correct leaf where the character is actually in. I have not measured much, but I expect it to be quite fast in practice, because the trees are never deeper than 32 nodes.
 Of course the fact that ropes are used is mostly completely transparent to the user (as usual in the pypy world :) ). Normal and unicode strings are implemented with them, but just from the behavior of these types the user has a hard time noticing. Of course there are significant changes in performance (in both directions).
Using ropes to implement strings has some interesting effects. The most obvious one is that string concatenation, slicing and repetition is really fast (I suspect that it is amortized O(1), but haven't proved it). This is probably not helping most existing Python programs because people tend to code in such a way that these operations are not done too often. However, with ropes it is possible to do something like this:
Of course the fact that ropes are used is mostly completely transparent to the user (as usual in the pypy world :) ). Normal and unicode strings are implemented with them, but just from the behavior of these types the user has a hard time noticing. Of course there are significant changes in performance (in both directions).
Using ropes to implement strings has some interesting effects. The most obvious one is that string concatenation, slicing and repetition is really fast (I suspect that it is amortized O(1), but haven't proved it). This is probably not helping most existing Python programs because people tend to code in such a way that these operations are not done too often. However, with ropes it is possible to do something like this:
awesome.
ReplyDeleteand what about pattern matching? for substring and regexps?
Substring matching should not be too slow, but there was no specific work on that. I think it only makes sense to optimize this once someone has a concrete application for that, because otherwise you don't know what you are optimizing for. So if anyone has ideas, I am interested to hear them.
ReplyDeleteGo and try this year's ICFP programming contest task (just the initial virtual machine part) using this.
ReplyDeleteAh, nice idea. Somebody should try this.
ReplyDeleteI'm writing up a GHOP task related to this; let me know if anyone is interested in mentoring it.
ReplyDelete(I'm asking for a CPython implementation, and separately the ICFP implementation)
--titus
titus@idyll.org